








El archivo robots.txt
Los buscadores de internet (Google, Yahoo, Bing, Altavista, etc) utilizan distintos algoritmos para recorrer e indexar los sitios web. Sin embargo, todos ellos comparten el punto de partida: solicitan al servidor que les envíe el archivo robots.txt
Si has revisado las estadísticas de tu sitio, de seguro has encontrado una petición muy repetida del mencionado archivo, que da como resultado un error 404 (archivo no encontrado).
Esto se debe a que el archivo robots.txt no existe por defecto en nuestro directorio raíz, sino que debemos crearlo desde cero.
Para qué sirve El archivo robots.txt ?
La existencia y el funcionamiento del archivo robots.txt responden a los protocolos del W3C (World Wide Web Consortium).
Nace con la intención de que el webmaster pueda ocultar a los buscadores aquellos contenidos que no desea hacer públicos, o aplicar reglas sólo para algunos robots en concreto.
Este archivo será el que indique a cada uno de los motores de búsqueda, los permisos y accesos sobre la estructura de nuestro sitio, que hemos decidido concederle para la indexación.
Es un archivo de texto y debe ubicarse en el directorio raíz del sitio, ya que ahí es donde lo buscarán los robots. Un robot no buscará nunca el archivo robots.txt en un subdirectorio, por lo que es inútil colocarlo allí.
En caso de que no se encuentre ese archivo, el robot considera que no hay ninguna exclusión y podrá rastrear y publicar todo el contenido del sitio web.
Una buena forma de probarlo, o de ver como un ejemplo real de estos archivos, consiste en apuntar el navegador hacia la dirección de tu sitio favorito, seguido del nombre del archivo.
Por ejemplo: http://www.opera.com/robots.txt y verás como resultado, el contenido de dicho archivo.
Cómo es el contenido del archivo?
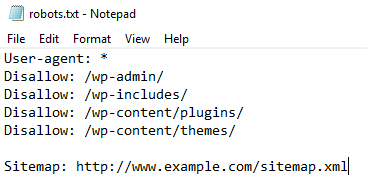
A no asustarse, ya que la estructura de este archivo es muy sencilla. Solo consta de dos campos, una linea User-agent y una o varias lineas Disallow:
User-agent: |
User-agent contendrá el nombre del robot de cada motor de búsqueda y Disallow será el directorio o archivo que vamos a proteger de la indexación.
Con esto sera suficiente para crear tantas reglas como necesitemos indicando para cada buscador que contenido queremos hacer público y cual no.
Veamos algunas reglas de ejemplo:
User-agent: * |
Este ejemplo es el mas permisivo de todos. El asterisco * significa TODOS LOS BUSCADORES. Además, al dejar Disallow en blanco, no estamos restringiendo nada. Implica acceso total para indexar todo el sitio web.
User-agent: * |
Este, por el contrario, es el ejemplo mas restrictivo. El asterisco * significa TODOS LOS BUSCADORES, pero la barra en Disallow, indica que desde el directorio raíz en adelante, estará todo prohibido. Implica que no dejaremos al robot indexar ninguna parte de nuestro sitio.
User-agent: * |
En este caso, definimos que todos los robots tendrán restringido el acceso a los directorios /cgi-bin, a /tmp y a /admin. De esta manera dejamos que indexen nuestro sitio, pero ocultamos de las búsquedas aquellos archivos incluídos en estos directorios.
User-agent: Slurp |
Este es un ejemplo un poco más completo, donde definimos que Slurp (robot de Inktomi) no podrá acceder a la carpeta borrador. Luego que Google no podrá acceder a tmp ni a admin, y finalmente todos los demás buscadores tendrán el acceso completamente restringido a nuestro sitio.
De esta manera, podemos tener un mejor control sobre las partes de nuestro sitio que los motores de búsqueda estarán indexando.
Antes de colocar el archivo en el directorio raiz de tu sitio, es una buena idea pasarlo por un validador para comprobar que no tenga errores.
Aquí tienes uno para probarlo: www.searchengineworld.com
Y para finalizar, una lista con los nombres de los buscadores más populares y la identificación que utilizan para sus robots (User-agent)
- Google: Googlebot
- Fast: Fast
- Altavista: Scooter
- Lycos: Lycos_Spider_(T-Rex)
- Inktomi: Slurp
- Wisenut: Wisebot
- Euroseek: Arachnoidea
- Alltheweb – FAST-WebCrawler
- Excite – ArchitextSpider
Una lista más completa y actualizada puede verse en: http://www.robotstxt.org
Si te gustó o te entretuvo el contenido de este posteo, haciendo un click en los avisos me ayudas a mantener el sitio con vida y a seguir publicando.
Y si quieres ganar algo de dinero sin esfuerzo, registrate en IPRoyal desde este banner y recibí 1 dolar de regalo al comenzar a usar la aplicación para generar ingresos pasivos.

Acá puedes conocer más sobre ingresos pasivos, que es y como funciona PawnsApp.